Dead Letter Queues


In today’s post I want to talk about what happens in EBA when things go wrong.
We have already learnt that our system will, basically, consume and produce messages.
The consumers and producers will be coded by our team, so this means that every now and then we will deploy a bug or a system which is not 100% aligned with another team requirements. Surely one way or another we will end up having a wrong message inside a topic or a queue and when this message is processed by a consumer something unexpected will happen.
So, let’s talk about Dead Letter Queues.
So, what’s the problem ?
Just imagine this scenario, as you can see in the diagram we have a consumer system that’s getting the events from a specific topic.
When the system consumes an event it executes some business logic, after that, it processes the next event and so on.
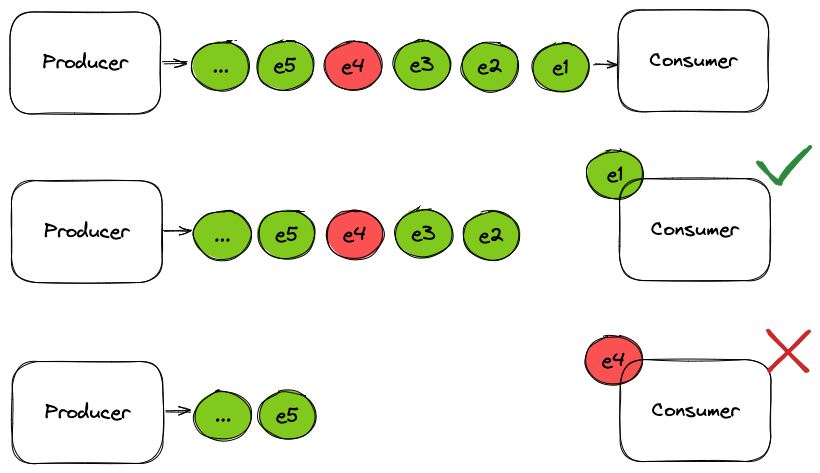
But, alas, the 4th event causes a failure in the processing system. This means that the system crashes when it’s processing it.
Why is it crashing the system? Could be several reasons, and we’ll list and explain some of them grouped by type:
Transient Errors:
- Timeout in a 3rd system.
- Db system is down.
- Network is down.
Permanent Errors:
- Permanent bug in the processing system.
- Wrong schema in the message.
- Wrong message altogether.
This might become a big problem, because, most probably this is what’s going to happen:
- The processing system will read the message from the queue.
- The processing system will blow up, throwing an Exception or something similar.
- The processing system will retry (or k8s will restart the pod, ...) . If the error is a permanent one, the retry/new instance/new pod will have the same problem.
- The processing system will read again (after rebooting, after …) and it will read the same message, as the read operations has not been committed.
- Go to 2.
Depending on the event processing system and development library you’re using to consume the events you might need to commit a read manually or rely on the library to do so.
Event processing system usually promise some reading / writing guarantees. Usually it's "at least once delivery": Better to deliver a message twice that none. But check your config and your documentation to make sure!
If we talk about Kafka specifically, when a consumer reads a message from the topic, the consumer "commits" the reading (the offset), so then Kafka knows that the next time that specific consumer requests data it can send it the committed offset + 1.
Usually the client consumer libraries commit the read transaction after a successful response to make things more transparent and less cumbersome for the developer, but as a side effect this means that if the consumer process launches an Exception that's not handled correctly the client library will not be able to commit the reading ack. So, the Kafka broker will not know that the specific offset has been read.
Of course, this is a very fast and generic explanation. You should go to your event processing system documentation and make sure you understand how your system handles this.
A message that causes a problem in the consumer, triggering this never ending loop of retries is called a “Poison Pill” and as we can see it's blocking the whole system. And as you probably know by now, event processing systems are not great in "deleting specific messages" from the queue.
So, what should we do in order to avoid this? We could surely ignore the Poison Pill, or to implement a Dead Letter Queue (DLQ from now on)
Ignoring errors tends to be a bad option 🤔
But, hey! up to you.
When an unexperienced developer finds herself of these situations the initial impulse might be to get the message that’s crashing everything out of the way. In order to do this we need to “process it successfully”.
A solution (bad, don’t do this) is just to create an if/then block in the processing code to identify the Poison Pill and just log it instead of processing it. As a result, the processing is successful, the read commit is executed and the system continues to process the following messages.
Well, that worked, but we just ignored one input. Surely that input was wrong and caused the whole system to fail and block, but why it was there in the first place? if it was just an error, then maybe it’s ok to ignore it, but if that message was an event containing some semantic information we are probably ignoring a business event that should be dealt with, and what’s more, if we don’t identify the root cause of that event, it might happen again.
DLQs, much better, but how do they work ?
The idea of a DLQ is pretty simple, it’s a new topic that holds the messages that break the system, or the messages that could not be processed successfully.
Basically it’s to get Poison Pills out of the way and into a place where they can be handled by someone.
We have now, the following scenario:
The processing system processes all the messages in the same way, but when it the error appears when processing the 4th event, instead of crashing it will send it to the DLQ.
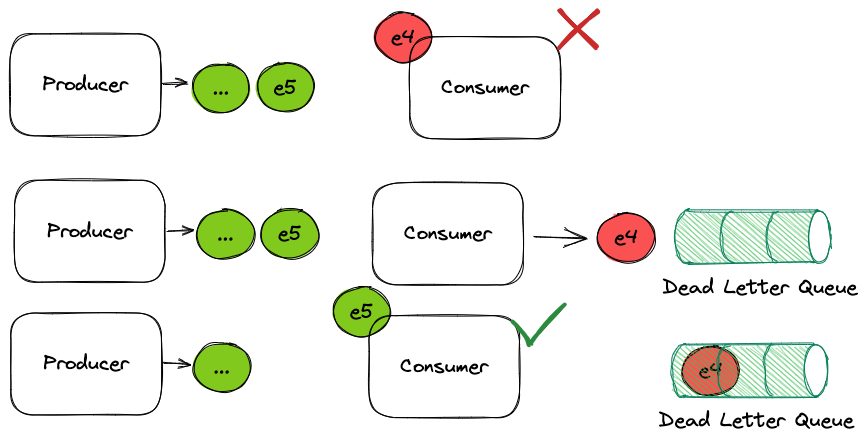
Usually a DLQ is just another topic in your messaging infrastructure with specific semantics. Hopefully it will not contain much data, so the topic should not be very big.
We need to adapt all our consumers though! When the processing logic detects a problem needs to understand that the event that has caused it needs to be sent to the DLQ. It could be as simple as:
public void process(Event event) {
try {
// do something with event.
} catch (Exception e) {
log.error("Something went wrong processing " + e);
dlq_handler.send(event); // send original event to the DLQ
// DO NOT RETHROW THE EXCEPTION
}
}This code does few simple things:
- Processes the message, if it fails it throws an Exception
- The exception is handled, it logs the error and it sends the original event into the DLQ.
- It does not rethrow the exception. This is important, as the flow needs to continue. An exception would probably break the flow causing a reprocess of the same event.
Another important point is that this topic might receive messages that contain wrong data, or it might even contain wrong formats or schemas (maybe somebody testing sent an XML message to a topic that was expecting JSON), so given that this topic is a DLQ let’s make sure that it does not contain a very rigid schema or we might be having problems sending wrong data to the DLQ, which would be pretty 😵💫
Now, after setting up a new message topic, customising our code to handle errors and put the original message into this new topic instead of retrying, the poison pill is gone.
Now what? What does it mean to have that data in the DLQ ?
What do we do with the data in the DLQ?
Dead letter queues are interesting because there does not seem to be any kind of standard on what to do with them. In the resources section of this blog post you’ll find several links that explain DLQ handling strategies by different companies that they developed in different scenarios, and you’ll see that some of them are massively different from each other.
One thing which is for sure though is that you need to know that you have data in the DLQ: The first step to solve a problem is knowing that you have a problem.
Some days later a stakeholder complained that the system was not creating all the expected rows in the database. We checked the logs and the system metrics for errors, but there was none.
After poking a little we realised that there was system had indeed a DLQ, and it contained around 80.000 entries of events that had failed.
And nobody had realised, ever.
Some message system libraries might detect errors in the execution, and send the original event to the DLQ automatically. Depending on the error handling code this might happen silently.
Keep in mind that DLQs are only used in error handling situations, meaning that errors are occurring and we need to be aware of them and respond accordingly. Consequently, even when using DLQs, we should also employ mechanisms like logging or metrics to inform the operations team that something has gone wrong and messages that should have been processed have been sent to the DLQ.
Nowadays there is no excuse to not doing a big resource investment in Observability.
Now, we know that something is wrong and we have some messages in the DLQ. Let's handle them.
There are different strategies. Myself, I tend to approach this situation trying to understand the nature of the error, and then, of course, the message semantics:
As stated before, we might want to split the errors in two groups:
- Transient Errors
- Permanent Errors
and after them, we need to understand the nature of the message.
Transient errors
Let’s imagine that the payload of the message needs to be processed by a third party system, and when the consumer tried to execute this process that 3rd party was not available. The system failed and sent the message to the DLQ.
In this situation a retry after some time would probably work. So, the DLQ could be handled by a consumer that would read the messages, wait some time to process them and then execute the same operation as the original consumer.
In this blog post by UBER in fact we can see a DLQ reprocessing strategy that consists on different levels of waits to retry operations until a threshold, where then the error recovery system gets a different strategy.
If we study carefully the system and what can go wrong we can come up with a DLQ handling strategy that can resolve error situations without human intervention.
So, transient errors are the ones that will eventually go away “if we retry enough”. The retry strategy might be in the system itself or it can be carried by a specific DLQ consumer.
Permanent errors
Unfortunately we are going to find different kind of errors in the system; the ones that will always fail, no matter how many times we retry.
These errors might be caused by lots of different reasons, but here I would like to focus on a special subset: the permanent errors caused by messages that carry a wrong payload (Poison Pills):
- The message is expecting a specific schema, but somehow a client is sending a different one.
- There was a bug in a validation part of the system and the message contains wrong data (negative ages, null strings, …)
- …
No matter how many times you retry to process the message, these errors will always cause an error in the consumer system. Which, unfortunately means, that the error handling strategy usually consists of accumulating the errors in the DLQ until a human intervention fixes the problem and triggers a reprocessing.
Message Semantics
Now we understand the two kind of errors that might send messages to the DLQ’s. We know that a “retry” might solve the transient errors and that you probably need human intervention to deal with the permanent errors.
Now it’s time to have a look at the message semantics!
Depending on the nature of the message we might have different situations that will influence our DLQ/error handling strategy. Let’s have a look at some of them:
- CRUD Operations
- Snapshot events carrying the full state.
- Commands for stateless actions
CRUD Operations
Let’s imagine that the messages that we are dealing with are status changes from a CRUD system, and that consumer gets the events and translates them into database operations:
- A create event in the system becomes a database insert.
- A change event in the system becomes a database update.
- A deletion event in the system becomes a database delete.
We could have the situation where the database is temporarily down (transient error). If at that time we try to process the “Create” event for a specific entity the system will fail, and would probably send the event into the DLQ.
What happens then if the database then comes online, and before the DLQ processes the “create” for that entity the main consumer receives an “update” operation for the same entity. That operation will also fail because that entity does not YET exist in the database.
In this situation, the events in the queue are ordered, and some might depend on others, so we cannot just trust that sending something to the DLQ will solve our problems.
You can do several things here. Maybe you want to blacklist all the subsequent events for that object?
In the CRUD situation this would work. If one event fails for customer '123', then you might want to blacklist it. This means that any event that you receive related to customer '123' goes automatically to the DLQ. This guarantees that you will not have inconsistency for specific business entities.
This also helps with the reprocessing, instead of reprocessing just one event you can then reprocess the whole sequence of events for that business entity, as all of them will be in the queue.
This is, of course if those CRUD operations are not part of a transaction. But that's another problem.
Snapshot events carrying the full state
Another scenario is that a system is sending snapshot events carrying the full state of a business entity. For example, the Customer Service might be sending the full Customer to a specific topic every time that a customer is created, or updated.
The processing system is getting those snapshots and putting them into a Cache, so other systems can use it, cool. It's a simple system, it just reads from the message queue and updates the cache.
Let's imagine that we have two updates from the same customer. The events will come one after the other.
The first message might fail, for any reason, so the consumer system would get it and put that message into the DLQ. Let's imagine that the second event, carrying the latest customer value works just fine. The system then updates the cache. And in fact, in this situation, we skipped a message, but the result is that the system is in a perfectly consistent and valid state.
After that, the DLQ consumer gets the first message that failed (the one containing a previous state) and reprocesses it, for example, sending it back to the main message queue. Eventually the system will read the message again, and update the cache, basically overwriting a valid snapshot with an outdated one.
Commands for stateless actions
Yet another scenario would be a queue that contains commands. A command is the order to execute an action on the consumer system.
Let's imagine that the action is sending a push notification to a specific user.
If the system processing the commands fails and sends some commands to the DLQ we might want to "just retry" them. This means that the DLQ would receive some commands, and then the DLQ consumer system would just get them and queue them back into the main topic, where they would be consumed again by the original consumer.
Let's imagine that the "re-enqueued" commands now work. The customer would get the push notification either way. Is that a problem? no it's not. In this case a simple DLQ consumer that just queues back the commands works perfectly fine.
General Strategies to handle data in DLQ’s.
At this point we understand that different kind of errors have different solutions, and on top of that we need to take into account the message semantics. This is why there is no single source of truth about using the Dead Letter Queue pattern.
So, we need to think about it case by case.
We've seen just 3 examples of different situations. All of them differ and they have different solutions. But I'd like to insist in some important points:
Observe and adapt
You need to observe the errors, and understand if they will happen again.
Maybe you have a problem because you deployed a bug. Fixing it will make that error disappear, fine! But what happens when the error that you get is something that occurs every now and then and there is no clear way to avoid it? Then I'd advocate to create a consumer for those specific errors that automatically gets the message and does whatever needs to do to fix it.
As we've seen in the different scenarios that might be a simple retry, a simple reinsertion to the main queue or maybe some business logic. Either way, this is something that could be automatic.
The consumer could detect this specific errors in the DLQ and handle them. For doing this we might consider having a specific consumer for the DLQ or even a specific DLQ for this specific kind of errors!
Handling the errors
The DLQ consumers might be complex in themselves. Maybe you're lucky and you just need to reinsert the message inside a topic again after some changes. If you're not that lucky you might need a system that actually has lots of business logic and might even has a human interface.
In these situations the best thing to do is create a consumer that gets the message containing the event and persist it into a database.
Messages queues are good for reading and writing ordered streams, but they are usually not great for reading specific messages out of order; also, we need to remember that topics usually have a duration, after which, the messages are permanently. We don't want our smoking guns disappearing into thin air.
Something that I've seen several times is a DLQ consumer that consumes a message and persists it in a database. After that, depending on the error it can automatically execute a mitigation action for that specific message.
If the mitigation action cannot be automated because that specific error requires human intervention, or if that kind of error is unknown until then, it just triggers an alarm.
Having these messages persisted in a database lets you do proper investigations of why the errors happened, as well as some nice metrics related to them. It's easy to throw a nice UI on top of that as well in order to execute manual actions on those events (send it back to the main queue, delete the message, ...)
To Sum up
In this post we've seen different kinds of errors that might end up blocking the message consumption in some parts of your system.
A possible way to solve this is using the DLQ pattern, which creates specific queues that contain the messages that caused the error.
These queues need to be monitored as, ideally, they should be always empty.
Handling the errors is hard to automate, and the error handling strategy should be thought carefully in order to find wrong strategies that would end up corrupting the state of the system.
Other resources


 Contributors to Wikimedia projects
Contributors to Wikimedia projects