Dual Writes


Today I want to write and discuss about the "Dual Writes" problem. It's not a new problem, and definitely not caused by the event based architectures per se, but it's pretty common to face it when teams start to use event systems.
A "Dual Write" is when a system needs to do a change (any kind of change, really) into two different external systems. The classical example would be to:
- Store a new record in a database table.
- Stream that new record into an event queue to be further consumed by another systems.
This, seemingly trivial, group of operations can cause big consistency problems in a system if not handled correctly.
While it's very easy to check that the record has been successfully written into the database, and it's very easy to check that the record has been successfully sent through the events systems it's pretty hard to check and control the different combinations of errors that can happen.
The Problem
First, let's imagine that the order of the operations is the one we wrote above. First the system writes the record into the database, and then, it writes the record into the message queue.
In the first error scenario, our system writes the record into the database and it gets an error. This is fine, as our code will most likely get an Exception and react to it, as a result of that, if the record is not stored into the database our code will skip sending the record to the message queue. Neat.
The second scenario is trickier. Our code writes the record into the database and the database successfully commits it. Then, as a result of that, the code writes the record into the message queue, but unfortunately the message queue is down. Now we have the record in the database, but not in the message queue.
This is a data inconsistency, and of course, we want to avoid that. We could always go back to the database and "revert" the change right? but that might be problematic as you'd need to revert a transaction, maybe delete a record, maybe revert an update. We can all agree that the situation can get messy pretty soon.
Flipping the order around does not help at all. We might write into the message queue first, but then if the database does not accept the change we'd need to remove that message from the queue, which is not something that we can do easily (if doable at all depending on the messaging queue technology).
Some solutions
Dual Writes are very common and have been around for some time. Probably they first appeared when systems had to write to typically, two different databases. This was known as the distributed atomic transaction problem.
There were several proposed solutions and implementations for solving this. The solutions basically consisted on a 2 phase commits protocol, which is a complicated protocol with lots of different error scenarios. While some implementations worked fine, the general opinion is that they were hard to get right and should be avoided due to the complexity they brought to the system.
Currently there are, at least, two accepted proper and simple enough solutions to avoid having data inconsistencies due to dual writes:
- Outbox Pattern (or Transactional Outbox Pattern)
- CDC (Change Data Capture)
Both are pretty different but have one thing in common. They base their correctness in making sure that the first step (writing into the database) is valid and then providing a mechanism that makes sure that the database is the source of the events.
We are moving from a situation where your code has the responsibility to manage this:
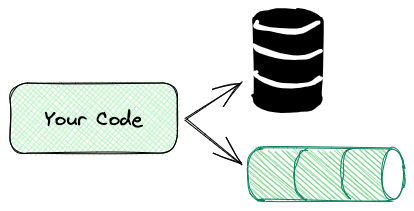
to a situation where the complexity of the dual write is managed externally by a reliable and resilient system:

Now, let's have a look at the two different patterns.
Outbox Pattern
(or Transactional Outbox) is a pattern that relies heavily on database transactions in order to ensure the reliability of the overall, distributed transaction.
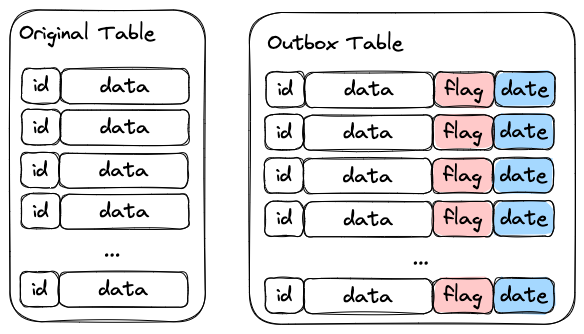
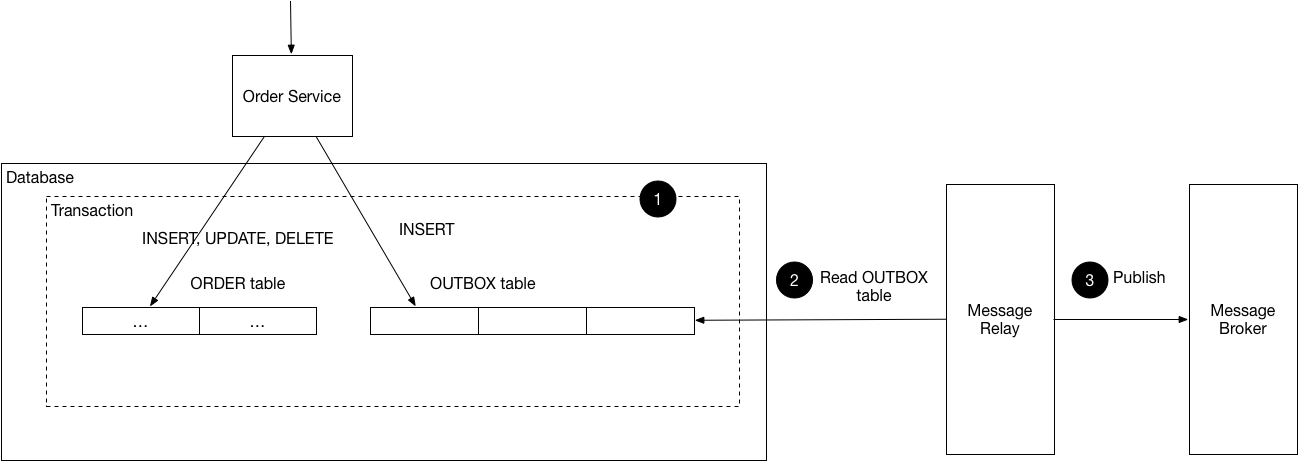
It consists of two different steps. Initially, the data is written transactionality into two tables: the "normal" table, and the "outbox" table.
The normal table is your business entity table. Nothing special, it will have the columns and requirements that the developer sees fit.
The outbox table is exactly the same with some extra columns, usually:
- A
flagcolumn: Which indicates that this specific record has not been sent to the streaming layer yet. - A
datecolumn: Which indicates the time when the record was written into the Outbox table.
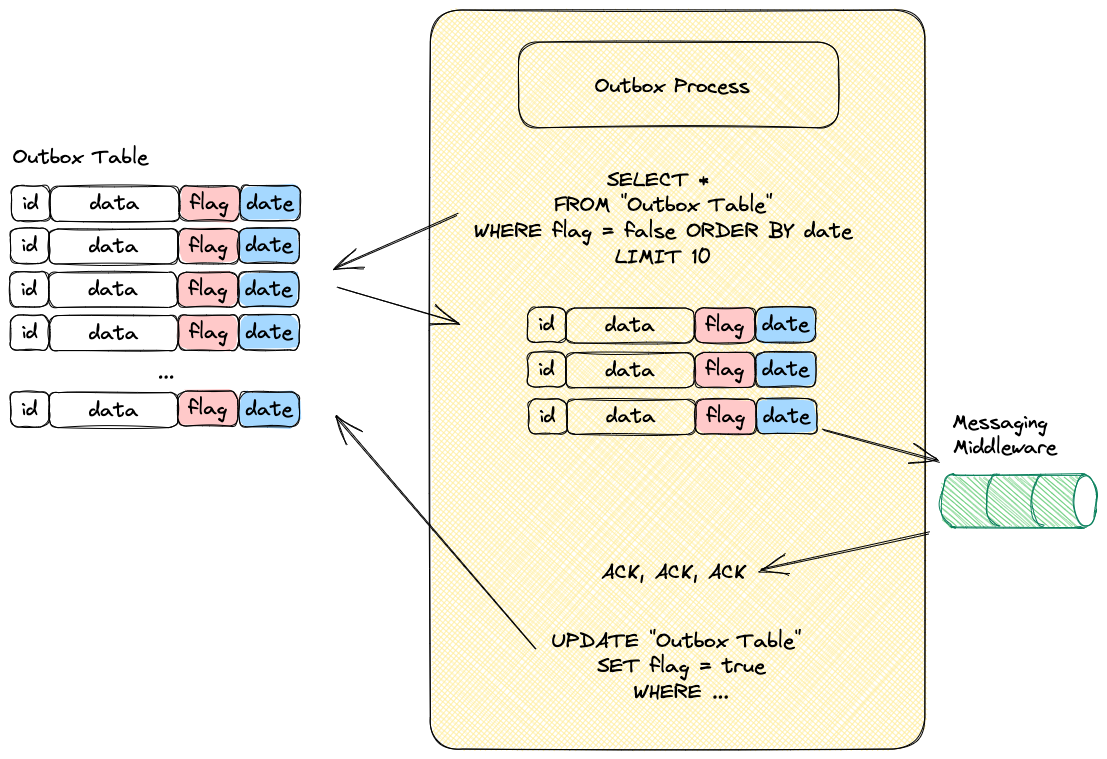
The second step is a different process that:
- Reads the Outbox Table, ordered by date, with the
flag=false: This will provide a list of records that have not been submitted to the streaming layer yet. You might want to batch those or limit the query. - You submit the records into the streaming layer.
- Upon confirmation from the streaming system that the record has been successfully sent, you update the
flagand set it totrue. This indicates that the record does not need to be sent again. - If the streaming layer fails, your process will not set the
flagtotrue, so the next time it runs it will get the records that failed again and will try again.
This also has the advantage of keeping the Outbox Table small.
Up to you and to your needs :)
Let's have a look at the following diagram, which illustrates the flow:
One of the big problems of the Outbox Pattern (and I'm not talking about the amount of work you need to do to implement it) is that you need to create a special case for hard deletes.
When you perform a DELETE operation you cannot do it transactionally in both tables. The original table will probably contain the record that needs to be deleted, but the outbox table might have already deleted that record. So, the DELETE would fail.
Unfortunately the DELETE operation needs to be handled separately and in a different way. Usually with database triggers (if your database engine allows it) that would insert the deleted row into the outbox table, that without transactional guarantees.
Change Data Capture
As we've just seen, the Outbox pattern is very verbose. It implies, amongst other things, create new tables and new processes that syphon the data from the transactional tables into the messaging queue.
CDC is a pattern and set of technologies that also allow systems to reliable perform dual writes.
CDC uses the native database technology to stream the database engine events to the outside of the database. As you can imagine this depends 100% on the database engine and version that you're running, which will make this pattern very easy to use, hard to use or simply impossible.
A CDC event will typically contain:
- The full table schema.
- The current state of the item
- If the database engine allows it, the previous state of the row
- The operation type (insert/delete/update)
Having this information lets you implement the vast majority of the use cases, also let's take into account that this pattern handles the DELETE operations perfectly fine.
When a DELETE operation is performed in a table the CDC system will create an event that contains the delete operation type. As simple as that. This is far more complicated to achieve in the outbox pattern.
Native Solutions
Modern architectures rely a lot on messaging systems. Of course, data needs to be stored in databases as well, which results in lots of teams facing the dual writes problem. Luckily, some database vendors have realised that having an easy and reliable way to stream data out of the database is a competitive advantage.
Some databases have CDC builtin, so it's just a matter of just activating it. For example, AWS DynamoDB has AWS DynamoDB Streams, which is exactly what we've been looking for.
Any change in a table item will send an event to AWS Kinesis for example. So, problem solved, as a developer you don't need to do anything.
Unfortunately not all the database engines have this feature, so we need to rely on an external system.
Debezium
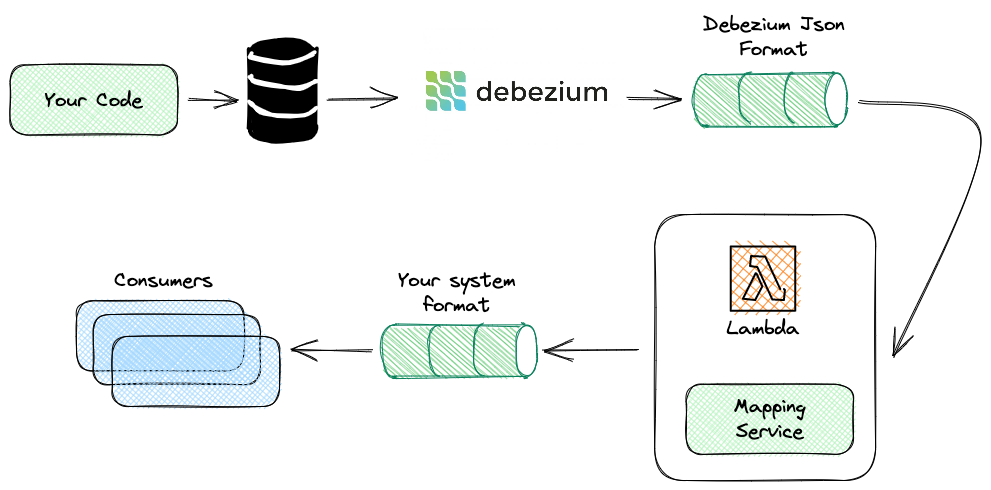
Debezium is an Open Source project, originally developed by RedHat that implements the CDC pattern.
This platform is able to listen for internal changes in lots of different databases, capture the event and stream it to a different set of messaging systems as well.
In order to use this in your system typically you need to:
- Install Debezium (or embed it into your code)
- Configure it with the specific database source.
- Configure it with the specific messaging queue sink.
When this is done Debezium will listen to the specified schemas or tables in your database and stream the changes into a message queue, usually Apache Kafka.
As explained in the previous section, Debezium will send pretty thick events into the messaging system using JSON by default.
This might not be what you want. Probably your consumers are expecting specific events schemas in different encoding formats.
While it's true that you can configure Debezium, and even embed Groovy code into the configuration to perform mapping operations teams usually rely on different components to do the mapping.
Is it worth it?
When your database system is able to provide, natively, the CDC events it's very easy to setup and very convenient. Unfortunately the other two solutions are far more cumbersome.
The Outbox pattern is fairly complicated, and using Debezium implies adding more systems to your architecture (Debezium itself, probably mappers, ...). While they both work great, we are adding complexity.
So, is it worth it?
This is an important question that we should always ask ourselves when working with complex architectures.
What's your use case? what's going to happen when (not if, but when) there is a problem in your infrastructure which results in a data inconsistency between what you have in your database and what's being streamed into other systems? Is it going to be critical? will somebody spend hours trying to figure out why this is happening while the company is losing money, clients or trust ?
This is up to you to decide.
Resources
General links
.png?itok=dUiALZtz)
 Contributors to Wikimedia projects
Contributors to Wikimedia projects
Outbox Pattern
CDC

