From sync to async, feedback strategies.


Generally one of the things that are most confusing when starting to use EDA's, coming from your typical REST architecture is the operation feedback, or the responses.
The REST architectural style, when used on top of HTTP has a predefined, very specific set of responses depending on the operation. The HTTP response codes are very clear and well documented all over the internet.
Let's have a look at some of the most popular, when all is good:
- HTTP 200, OK: The request succeeded successfully. Usually in when the request is a POST it returns the new resource in the response body.
- HTTP 201, Created: The request to create a new resource was successful and the new resource has been created. The new request (or its ID) is returned in the body of this response. It's very similar to the
200response, but more specific to POST requests. - HTTP 202, Accepted: The request has been accepted by the server and the server has initiated the processing.
Let's have a look at some of the most popular, when the client did something wrong:
And, at last, but not least, some of the most popular, when the server did something wrong:
- HTTP 500, Internal Server Error:
- HTTP XXX, Timeout: I've seen the timeouts implemented in so many ways (408, 503, 504, ...) that I don't know which one to choose. The idea is the same though. The server takes too long to process the request that there is a timeout.
Any experienced developer knows how to act when a client gets these responses.
My personal rule of thumb when writing REST interfaces clients is:
- 20X: Ok, let's continue.
- 40X: My fault, I need to review something on my end (the client)
- 50X: Not my fault, I need to complain to the dev team handling the server.
Ok, given this we can easily build application flows with their proper error handling strategies.
What happens, though, when instead of writing a synchronous REST client we are sending command messages to a broker topic? These are totally asynchronous commands, you send a command in a topic and that's it. We don't have any guarantee of reception and we don't know what happened on the other end of the topic.
This has very serious implications, and our systems will need to adapt accordingly when migrating from a sync flow to an async EDA based flow.
Let's have a look at some examples, grouped by the kind of response family, that we might find when designing our systems.
Successful responses
Let's start with the happy path. Everything works fine.
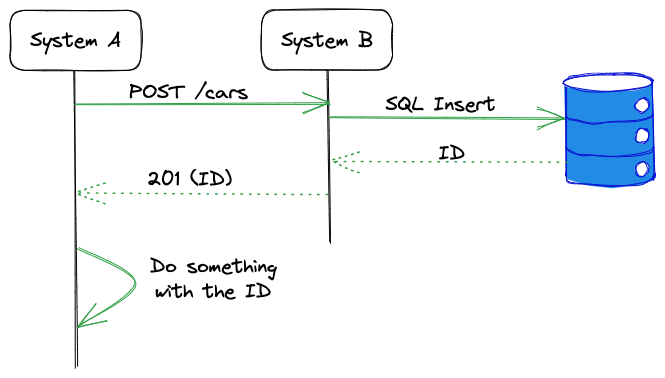
In a REST system the interaction would be trivial. The client would issue a POST request to and endpoint. The server would create the resource accordingly, and then returns an HTTP 201 with the new resource ID or the new resource itself in the body. All good, the client can continue.
Let's try to see what would this flow look when using Kafka.
In this situation the client, instead of doing an HTTP request with a POST would send a command to a specific Kafka topic with the payload to create a new resource. And that's about it. The Kafka client library will let you know that the message reached Kafka successfully, but nothing else. We don't know if the event has been consumed yet, or if the processor succeeded or failed.
This might be OK for some situations (fire and forget), but in most interactions the client will need some feedback.
During this example we will assume that the client (`system A`) is creating a specific entity (a Car), and it will need its ID in order to continue its flow.
The client will create a command that might look like this:
{
"brand": "Ford",
"model": "Fiesta",
"plate_number": "ABCD-23"
}What could we do in this situation? well, the easiest solution is implement a service that consumes this specific Kafka topic (system B), it fetches the commands and then creates the object. Once the object has been created (stored in a database, for example) this same system could send a en event through an event topic to specify that the operation succeed.
Things get interesting when we need to decide what's in the payload. First things first, who's going to consume these events?. Maybe the same system that sent the creation request (System A). But, how do know, amongst all the events which is the event that we need to fetch. System A wanted to create a specific car, and it's listening to a topic which contains, potentially, loads of car creations. Then we need to filter. Let's have a look at a potential payload:
{
"car_id": "UUID-1",
"created_at": "xxxx-xx-xx:xx-xx-xx"
}This would not help us in any way. We know that a Car was created and it got an ID, but we don't know if this is OUR car. Let's try to make this better:
{
"car_id": "UUID-1",
"plate_number": "ABCD-23",
"created_at": "xxxx-xx-xx:xx-xx-xx"
}This is better, now we know that this is our car because the feedback event contains a unique id that identifies our specific car. In this case, the plate_number. So, the consumer of the feedback topic only needs to filter the events and look for the one it needs.
This situation was clear, because the System A provided an ID that then could be used to filter. But what happens if this is not the situation? there could be situations where the Business object itself does not contain any unique id! Well, then in those situations probably a good idea is to just add an artificial UUID with the command, then we are back on track.
This is complicated and probably cumbersome to implement. A system that sends to Kafka needs to block, listen to another topic and filter potentially thousands of events to find just one, and then continue.
On top of that, this works on paper we might discover problems in any real environment where we run this design in the cloud. Two problems (at least):
- Node goes down. We might have a bug, we might redeploy, we might do tons of different things that would trigger this system to go down and start again. This system is stateful. It sends a message with a specific ID, and needs to receive a message with that specific ID. What happens if the system goes down in the middle? when it starts up again, how does it know that is listening to that ID?
- Number of instances. Let's imagine that this system is running in a multi-instance setup, basically there is more than 1 system running at the same time doing the same to share the load. Let's get an example where there are 2 instances of
System Aexecuting in parallel, both are sending commands in the same topic. The events are received bySystem B, which will issue the feedback events to the feedback topic, which is going to be read by the twoSystem Ainstances.
What happens if instance 1 issues a command, but the feedback is read by instance 2? this means that both systems need to maintain a shared state by using an external storage...
This is getting complicated, very complicated, for a happy path. The REST version is literally two lines of code, while the EDA version is far more cumbersome and needs to leverage on external systems for storage. How is this possible?
If we are using an async technology we need to adapt the flow. This means that we need to decouple the systems.
This is the sync flow:
And the async flow should be something like this:
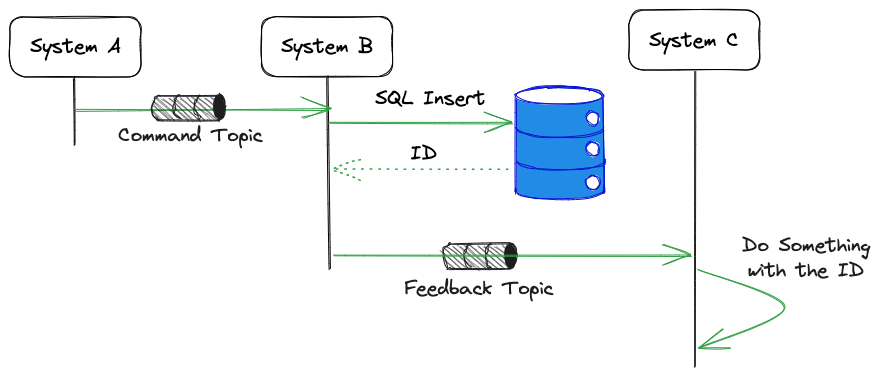
System C being a simple microservice, or even maybe a serverless system.
In following posts I'm going to talk about how we can handle errors scenarios.
Also, if you have time watch this amazing talk by Rebekah Kulidzan at GOTO 2022, where she explains the importance of thinking asynchronously when using event based architectures.