Introduction to Event Based Architectures


In this post I want to introduce the architectural concept of an Event Based Architecture (EBA).
An architectural pattern in software engineering is a way of designing software systems in a consistent way and with an objective in mind. The main idea is to be able to reuse known working design structures to reproduce solutions, because you know, if something worked once, it will hopefully work again.
Here I will be explaining different advantages and disadvantages of this specific architecture.
The full architecture, as the name implies, is based around the concept of events. And, an event is something that already happened.
When we work of computer systems we tend to think of command structures (do this):
- Press a button to send the email that you’ve written in the editor.
- Press a button and print the document.
- …
These actions have direct translations to events though:
- Send email button pressed, so the email needs to be sent.
- Print button pressed, so the document needs to be printed.
- …
As I’ve shown in these examples, I have actions, which can be converted into events. And of course, our systems react to these events with further actions that will generate their own events once they have completed successfully.
This is very clear and straightforward, very easy to understand. So, how let’s see how this simple concept translates into software engineering architectural patterns for designing big, distributed software projects.
First let’s think of a very simple, and probably naïve, example of an e-commerce site that illustrates the ideas.
You press the button to add one item you like into the basket. If we use the “direct reaction” thinking we go with:
- When the customer presses the button the system needs to recalculate the total amount of the command.
- When the customer presses the button the system needs to update the basket.
- When the customer presses the button we need to go to the warehouse to put the item on “hold”
So, we have one system that needs to do lots of different things. Nowadays, in the microservices era, these different actions will be most likely performed by different systems, that might be online or offline, or have different processing speeds. What happens if one of them is down? or takes too long to respond? should the whole process wait for it?
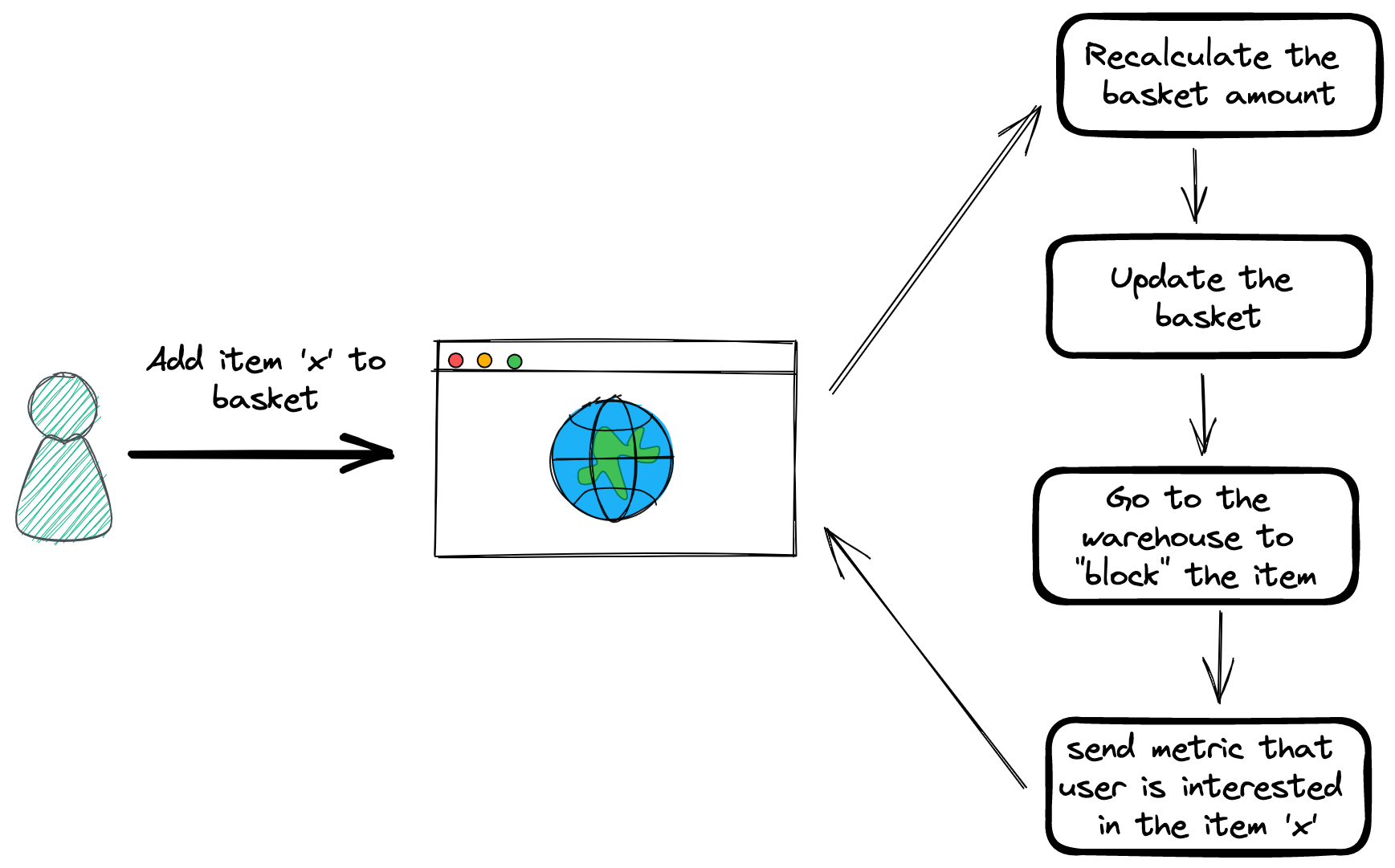
This is what we call high coupling in a synchronous system. The operations happen one after the other, and the total time of the use case is the sum of all the different operations.
Of course the are tons of ways to improve this, but conceptually this is what happens.
I’ve specified that this solution has high coupling, which is something bad. It means that any change done in one of the individual services will affect the services that directly communicate with them. The ideal scenario is a loose coupling one, where the changes done in a specific service are totally independent, and the services that communicate with it are not affected in any way.
Now, back at our EDA example, if we think in the “reacting to events” way the situation is different.
The main system will communicate that something happened, so the systems that are interested in that kind of event will react to it. When the system communicates the “item added to basket event”:
- The system that recalculates the total amount of the command will react to it and do the action.
- …
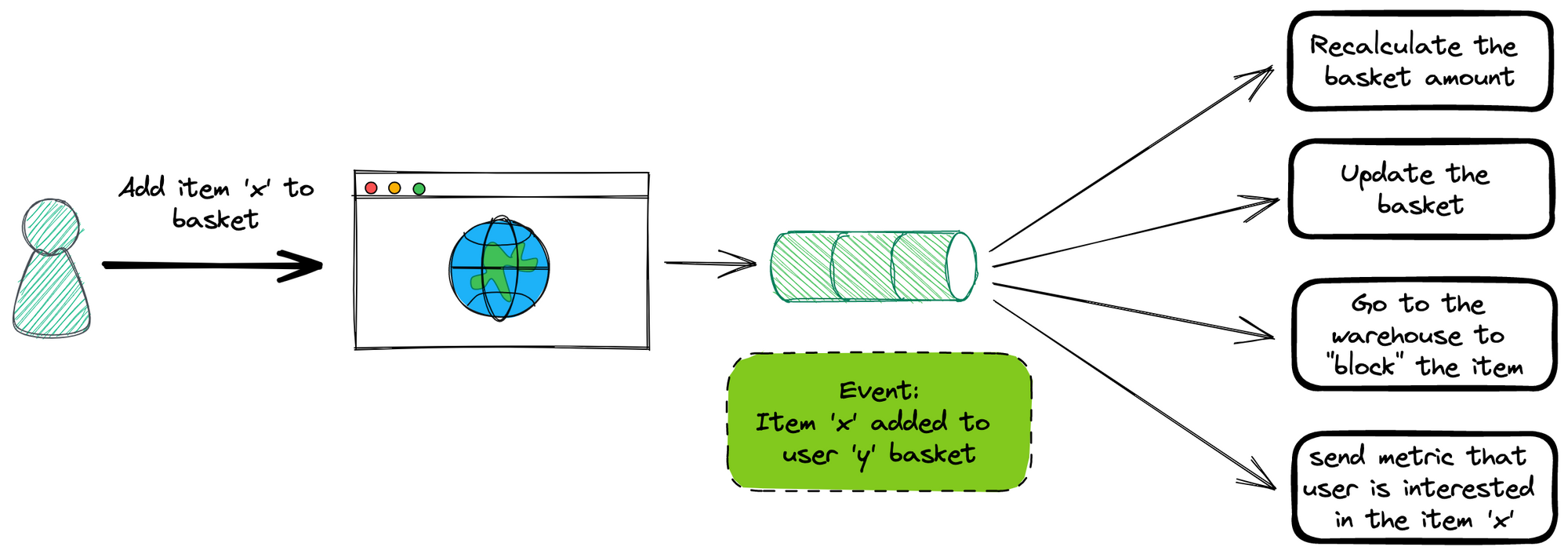
From the point of view of the main system it went from orchestrating the flow and waiting for responses (and reacting to errors) to send an event and expect the other systems to do their work and do the necessary changes.
We went from a coupled synchronous system to a decoupled asynchronous system. Even we could say that we went from an Orchestration Pattern, to a Choreography pattern.
We could even say that there is a direct translation from the synchronous architecture to the asynchronous one, but this is not always clear.
Let’s have a look at some examples to further illustrate this high coupling / loose coupling if we use this architecture correctly.
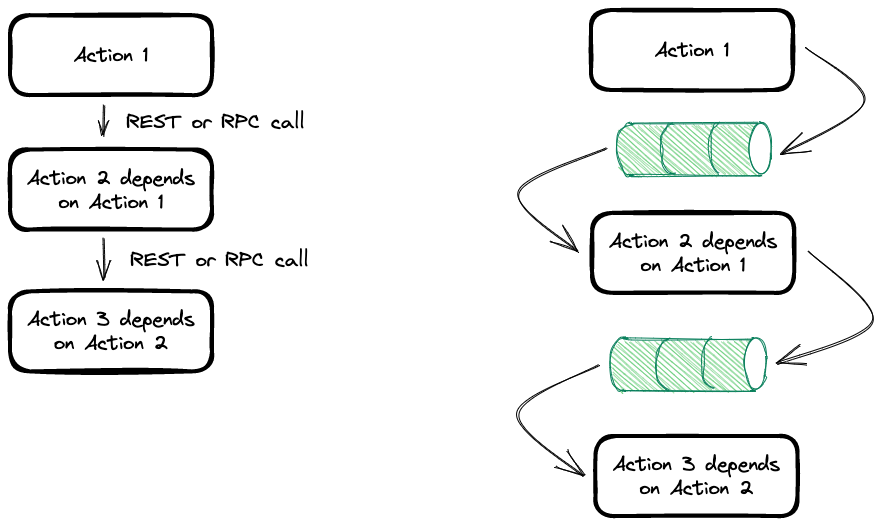
All sync and dependant operations
In this diagram we have 3 tasks, but alas, each task is dependent on the other one. Translating this into an EBA doesn’t improve it much.
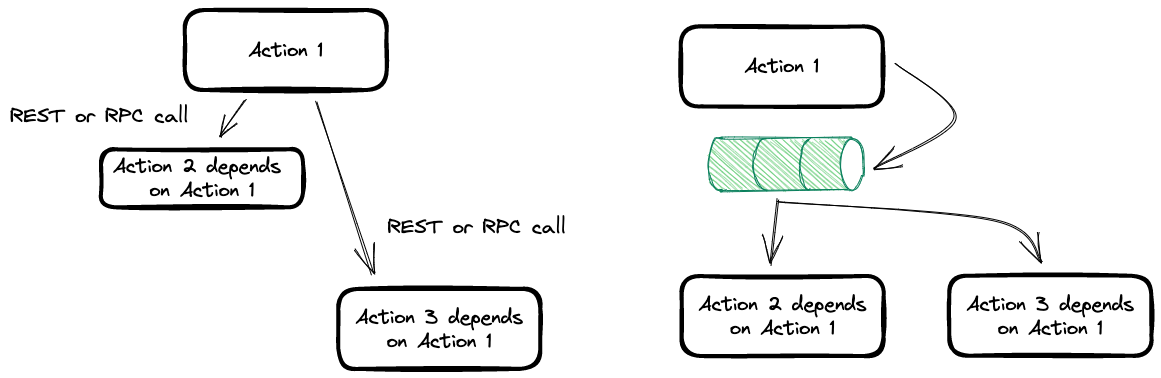
Independent operations
In this diagram we can see an immediate advantage of using this communication pattern. Basically we are able to parallelise and make the orchestration simpler.
Back to the events
After talking about coupling, let’s get back to our main character.
The event is something that’s created when an action has happened in the system. An important action, so some system probably needs to react to it. We are mostly talking about business events here, actions that triggered an important situation in your domain.
The event itself is a message from A to B (and C, D, ….) that contains data, in fact, it needs to contain all the needed data so other systems can fully react to it. We were talking about decoupling some paragraphs before, so something that we don’t want to happen is:
- Component 1: Hey! this happened!
- Component 2: Ok, I’m interested, give me more info about it!
- Component 1: So, this user
user1234got created in the db.
We introduced coupling again in this example, as component 2 is highly dependant on component 1. Instead we should be doing:
- Component 1: Hey, this user
user1234got created in the db. - Component 2: Ok
The first scenario only contained the “event type”, but not enough information about it. Then component 2 needed that specific information so it had to go ask for it. In the second scenario the event contained the “event type” and more information, basically all that was needed.
Of course, in the real world there are events that carry little information like this example, or events that are massive featuring up to some megabytes of data.
In these architectures we have tons of events, as they happen continuously. The services that interact with them use them as input as an output as we can see in the diagram, basically creating a constant Stream of Events. This is why, some people like to call these architectures “streaming architectures” as well.
Designing the events, with their data and their semantics is a full topic and it probably deserves at least one full blog post about it. But not today.
How do these concepts translate into a real big distributed system?
The Message Broker
We have several ingredients in here, events, systems that communicate with them. But how do they do that? With the Message Broker.
The message broker is the piece of software (you don’t want to code yourself) that enables this kind of communications between the different components. Is where systems send the events and from where the other systems read the events from.
At the time of writing there are a ton of good solutions, and if you are reading this probably have heard about some of them already:
The list is huge and all of them have different characteristics and operational abilities, such as ways to organise the same kind of events in the same “queues” or “streams”. This is yet another blog post by its own. And choosing one over the other is not a decisions that can be taken lightly.
Producers and Consumers
The of course we have the different systems that send events or get the events from the broker. We will call them producers (of events) and consumers (of events) from now on. Logically, a producer is a system that sends events might be one, might be tons, with a specific format or different formats, … into the broker. And a consumer is the system that consumes one or more types of events (combining them for example). And of course, we can have systems that consume events from the broker, transform them into something else with some business logic and produce a different set of events that will be sent to the broker again, so they can be producers and consumers at the same time.
Now we have the basic concepts to start doing a bigger architecture based on them. This architecture, if done correctly and if we don’t fall into anti-patterns, will:
- Provide a better scalability: Is one system too loaded? just spin another one and the message broker will seamlessly share the load between them.
- Provide better resiliency: Is one of the consumers down? no problem, the events will be stored in the message broker. When the system is back up again it will consume them where it last left.
And in the end, an event based architecture might look like:
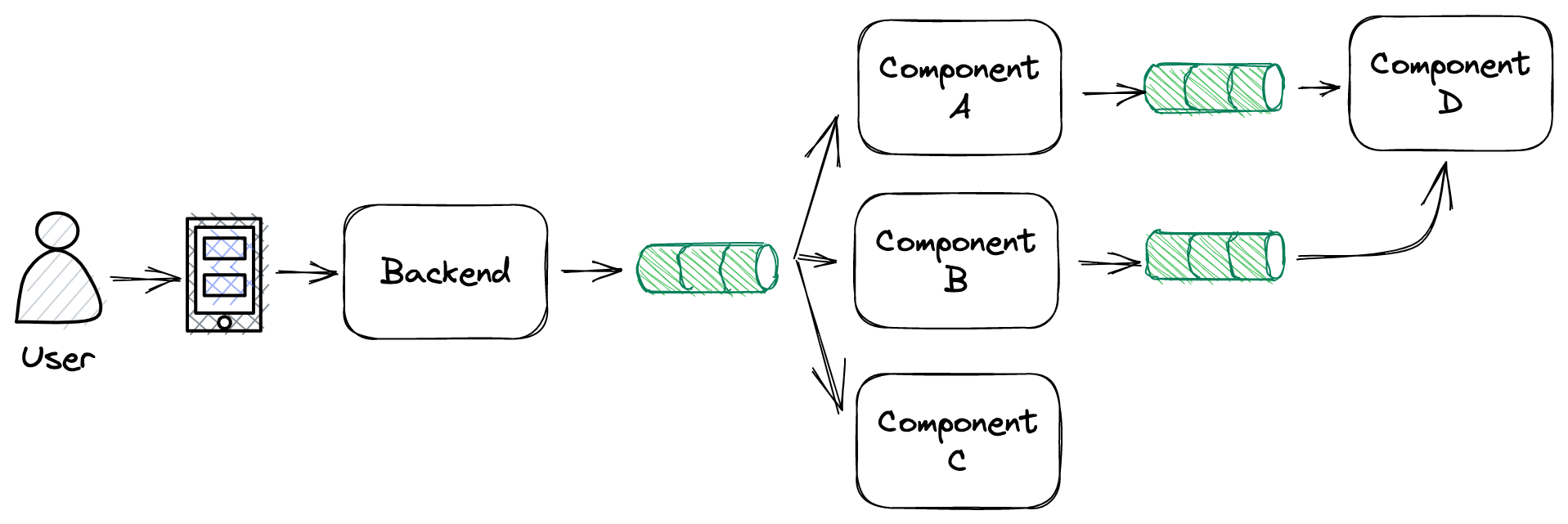
Where we have a little bit of everything:
- Producers, like the
Backendcomponent that reacts to the user actions and creates events. - Consumers, like
Component Cwhich reacts to the events sent by theBackend - Components that consume and produce like
Component AandComponent Bthat read the events, process them and create other kind of events. - And even a
Component Dthat consumes from two different message streams in order to join them.
The main takeaway is that you can build a very effective system if you successfully design it using your business events.
To sum up
This blog post is a gentle and conceptual introduction of how EBA works. As you’ve seen this is by no means any in depth tech tutorial.
If you are interested in these architectures, my recommended next steps are:
- Understand how a message broker system works. Get one, play with it.
- Choose your language, choose your library.
- Think about the events, and draw a lot. There are several blogs and information about how to define the events. I would say that this is, in fact, the most critical aspect of these architectures. In order for them to work you really need to understand the domain and what needs to be done as a result of each event (or combination).
Also, come back for more because I will be exploring the tricky parts, the corner cases and the not so pretty parts of the EBA.