Write Ahead Logging
What's a Write Ahead Log and how to implement one.


Databases are amazing software tools. There are currently databases for all tastes and flavours. Relational and non relational, specific ones for time series, key-value stores, document stores. Most probably, whatever your needs are, you have a database tailored for you.
This does not mean that they are simple or trivial software systems. Other than providing safe storage databases also provide querying features, and tons of other functionalities, without getting into details of distributed databases and data stores.
Database research has historically been a huge topic in computer science, as a consequence we have tons of interesting algorithms and ideas that have been designed to solve all kind of storage needs.
So, if we look inside a database we will be able to find very cool stuff, and, if we are lucky, we might be able to use these great, and proven ideas to other kind of software systems.
Today I want to talk about Write Ahead Logs, which is a family of patterns and techniques that databases use, typically, to provide Atomicity and Durability. So, in this post we will see:
- How Write Ahead Logs (WAL from now on) work, a very simple idea.
- How they are implemented, not that simple. (This part will be presented with explanations + an open source codebase that implements the ideas)
- How we can use them outside of the database world.
How WALs work.
The WAL idea is pretty similar to the "Event Sourcing" architecture, where a series of events or commands brings a system from state A to state B in a deterministic way. If we apply these events in the same order to a system which is in state A we will always reach state B.
If we evolve this idea into a complex software system we will see that every time that a command is executed in order to evolve the state there are lots of things that can go wrong. We can find situations that the change was applied, where the change was not applied and situations where the change was applied to an intermediate point rendering the system inconsistent.
So, in order to do things right and deterministic the WAL technique persists the event into durable storage before applying the change into the state. If the system crashes during the update, we can always go to the durable storage, retrieve the change and execute it again.
Basically a WAL is based on a "append-only, auxiliary, disk resident structure".
Let's review this sentence because it contains lots of interesting information:
- Append Only. This data structure can only be expanded, which is one of the simplest operations that you can do on a data structure, specially if this structure resides in a physical storage. WAL relies on being fast to not to be a bottleneck for normal operations.
- Auxiliary. The WAL does not add "additional features" to the normal operations that succeed, it's just a technique to recover from errors and improve resiliency. Nothing else.
- Disk Resident. As we said, the technique relies on making sure that the system can recover from the stored data, so the data needs to be securely persisted into durable media so it can survive failures.
An example of the WAL in action:
- A user writes a change into the database.
- The database receives the change.
- The database writes the change as a "command" in the WAL.
- The database writes the change in the proper table, but alas, as the change is written into the system, somebody trips a cable and the server shuts down.
No problem, because when the database system reboots will check the WAL file and realise that a change was not applied. The system will get the command from the WAL and will execute the change into the engine.
While this is a very simple idea we just described the happy path. Any experienced developer will realise that there are lots of things that can go very wrong and that this technique needs to be implemented carefully.
How WAL's are implemented.
As we've seen, the initial part of the technique is not rocket science, and given that we are using with proper programming languages and proper operating systems is pretty simple to make sure that a change is actually persisted into disk. So, the initial step is:
- Receive the operation.
- Persist the operation into disk. Make sure it's persisted.
- Continue with the normal operation.
Let's stop the explanation before we get into the gory details and let's see some code.
Let's go for the happy path. In this case we are going to implement something that's very simple.
We can start with an interface that defines the WAL operations. Currently we are going for the basic one, so let's do a write operation that will accept a key and a `value`, for keeping things simple we'll start with only accepting `String`.
public interface Wal {
boolean write(String key, String value);
}https://github.com/lant/wal/blob/0.1/src/main/java/com/github/lant/wal/Wal.java
Now we will implement this interface:
public boolean write(String key, String value) {
// "serialise"
String serialised = key + "-" + value + "\n";
try {
// write into the file.
this.fileOutputStream.write(serialised.getBytes());
// make sure that the data is actually persisted into disk.
this.fileOutputStream.flush();
} catch (IOException e) {
logger.error("Could not write into WAL file", e);
return false;
}
return true;
}https://github.com/lant/wal/blob/0.1/src/main/java/com/github/lant/wal/text/TextFileWal.java
A simple example of usage can be found in:
public void writeKeyValue(String key, String value) {
if (!wal.write(key, value)) {
throw new RuntimeException("Could not persist data.");
}
data.put(key, value);
}https://github.com/lant/wal/blob/0.1/src/main/java/com/github/lant/wal/example/Database.java
Full code in: Tag v1 of the Github repo.
As you can see I went to implement the basics to get up to speed with the concepts. Currently (tag: v1) is a toy project:
- Serialisation: The key and the value is not serialised, just dumped as text on the file.
- File: The file is a bunch of text lines terminated by
\n
Once we have successfully implemented and tested the basics, let's think about the real tricky parts. In this post we are going get deeper into:
- The WAL is always increasing in size. The WAL is a continuously appending data structure, which means that it is going to get bigger and bigger. What should we do with it? when is it safe to archive/delete ?
- How to use a WAL to recover the state after a crash? This might seem simple, but it's not, there are lots of corner cases and the "brute force approach" will not always work.
- How to make the WAL efficient. The WAL is an auxiliary data structure that we use in order to improve the resiliency of our system. Of course, we don't want our system to get more fragile and slow because of this!
Keeping WAL file size at bay.
The WAL file, or files by definition will always grow. And this growth needs to be efficient and fast. That's the reason why we always append data, because appending is fast and easy.
If we had to manage deletions or updates in the physical file the operations would be far more expensive, so even if we delete a record, the file will grow as we are going to record the "delete command" into the log.
Every now and then we will need to do some cleaning. And we will be able to perform these cleaning operations when nobody cares about the data in the WAL file. And when it's that? it depends on the system.
Let's have a look at two different cases:
- Single system: This is the simplest scenario, where a single system is processing the requests. This system might be using a WAL to improve resiliency, so this system is the only one that would be consuming the WAL in case of error. The consequence of this is that when the system has successfully committed the data into the main storage system (the tables, ....) the data in the WAL can be discarded as it would not be helpful in case of recovery as the data has already been saved.
- Distributed system. WAL's make much more sense in a distributed system such as a distributed database. In the single instance service case the data is written into the WAL and immediately processed and store in the main storage system (in case of a DB for example). This is probably very fast.
When we are talking about a distributed system, the data needs to be saved into this specific node and then replicated into other nodes of the system. The data replication will be slower for sure, as it will need to access the network. Accessing the network is slow and dangerous. This is the situation where WAL's shine. In case of network error we can always retry the command from one instance to the other from the WAL.
As we have just seen, we will only be able to delete (or archive) the WAL when all the clients have successfully "committed" the command into the main storage.
So, if we go back to the code this means that we need to do lots of different things:
- The file is immutable, so we cannot delete parts of it. The ideal would be to delete the full thing. So, we'll have to implement the functionality to limit the size of the files, and when we reach that size we will just create a new one and continue from there.
- The WAL interface will implement a
commitmethod that will indicate that a record we just stored in the WAL file is good to be deleted. - There will be a process that deletes files once we know that all the content of that file can be discarded. Let's think about this carefully as this needs to be innocuous to the rest of the code as we don't want to make our system slower because we are checking and deleting files.
Let's get back to the code, you'll see that there are tons of changes that need to be made.
First thing, we'll have to implement the "rolling" wal file feature. This consists of two parts. The first one is detecting that a WAL file is full and that we need to start a new one. The second part is rolling them and deleting them.
For doing this we'll modify the TextFileWal.java file. We'll introduce a MAX_FILE_LENGTH size (in the example, 1mb) and we'll add the capability to detect if there are previous files in the directory at start-up time. If there are existing files the system will open the latest one for storing the new data.
// let's see if we already had some WAL files in there.
OptionalInt previousIdx = walFileUtils.getPreviousIdx();
if (previousIdx.isPresent()) {
// check the size.
if (Files.size(Path.of(baseDir.toString(), getWalFileName(previousIdx.getAsInt()))) < MAX_FILE_LENGTH) {
// continue with this one
currentWalFileIdx = previousIdx.getAsInt();
logger.info("Found a previous wal file idx, we'll continue with it. Starting at: " + currentWalFileIdx);
} else {
// let's go for a new one.
currentWalFileIdx = previousIdx.getAsInt() + 1;
logger.info("Found a previous wal file idx, too big to reuse. Starting at: " + currentWalFileIdx);
}
}The other important part is being able to detect that a file is already full, so we will just start a new file and continue writing in there:
// write into the file.
this.fileOutputStream.write(serialised.getBytes());
// make sure that the data is actually persisted into disk.
this.fileOutputStream.flush();
// check size
if (Files.size(this.currentWalFile.toPath()) >= MAX_FILE_LENGTH) {
// roll file
currentWalFileIdx++;
String nextFile = getWalFileName(currentWalFileIdx);
logger.info("Rolling wal file to " + nextFile);
this.currentWalFile = Path.of(rootDirectory, nextFile).toFile();
this.fileOutputStream = new FileOutputStream(this.currentWalFile);
}This will allow us to have a directory full of WAL files with all the data, but wait, this is not what we want. We want them to be deleted once the data is already processed.
In order to detect when a record has been successfully processed (and so, deletable) I'll change the way I'm serialising data into disk. I'm going to add a key to each record, and it's going to be a timestamp. Also, I'm going to add a new method to the WAL interface to let the system commit a record that has already been processed.
The idea behind this is to be able detect that the record that was committed at a specific time has already been saved. This means that all the records that were committed before can also be deleted.
For this specific project a millisecond timestamp and understanding that if we commit a record it means that we can delete all the previous ones is peerfectly fine, but as always these kind of assumptions should be considered thoroughly before implementing a real system.
So, the code that adds the commit functionality:
@Override
public void commit(long walId) {
cleaningProcess.setLatestIdx(walId);
}You'll see that there is a new class, called CleaningProcess, this is a system that will run in another thread that will take care of the deletions.
We don't want to slow down our system or block it because we have filled a WAL file and we need to delete the old ones, so I've implemented it as a very simple background process that runs every now and then asynchronously without blocking the main thread that handles the client requests.
It's use is very simple. It will receive (continuously) the latest key that has been saved by the system. Then, when the system executes it will fetch the latest value and it will look in all the WAL files to detect which can be deleted.
For this specific implementation I've decided to use a time based schedule that will try to clean files every 10 seconds.
The interesting part is this one:
private void cleanup(long latestIdx) throws IOException {
logger.info("Starting clean up process");
// list files in order
List<Path> walFiles = Files.list(Path.of("/tmp/wal/"))
.sorted().collect(Collectors.toList());
// exclude the current idx
walFiles.remove(walFiles.size() - 1);
// for each file:
for (Path walFile : walFiles) {
String lastRecord = "";
String currentLine = "";
try (BufferedReader fileReader =
new BufferedReader(new FileReader(walFile.toFile()))) {
while ((currentLine = fileReader.readLine()) != null) {
lastRecord = currentLine;
}
}
long lastRecordIdx = Long.parseLong(lastRecord.split("-")[0]);
if (lastRecordIdx < latestIdx) {
logger.info("The last idx contained in " + walFile.getFileName() +" is smaller that " +
"the commit record ["+lastRecordIdx+"]. Deleting WAL file.");
Files.deleteIfExists(walFile);
}
}
}That will go through the files, look for the ones that are full of committed data and remove them.
Restoring state after a failure
Until now we have been laying the foundations to build the main use case of the write ahead log, which is being able to restore a state when a problem occurs.
In order to do this we will need to do several changes into the system. First I focused on changing how we test this.
Up until now the "Database" class was a dummy class wrapping a HashMap. It kind of did the trick but we using this implementation it's quite impossible to test the recovering scenario.
If you have a look at the version 0.3 tag you'll see that the Database class is far more complex. Let's not get into details about this, but in order to represent a real database or a real consumer I've created the following system:
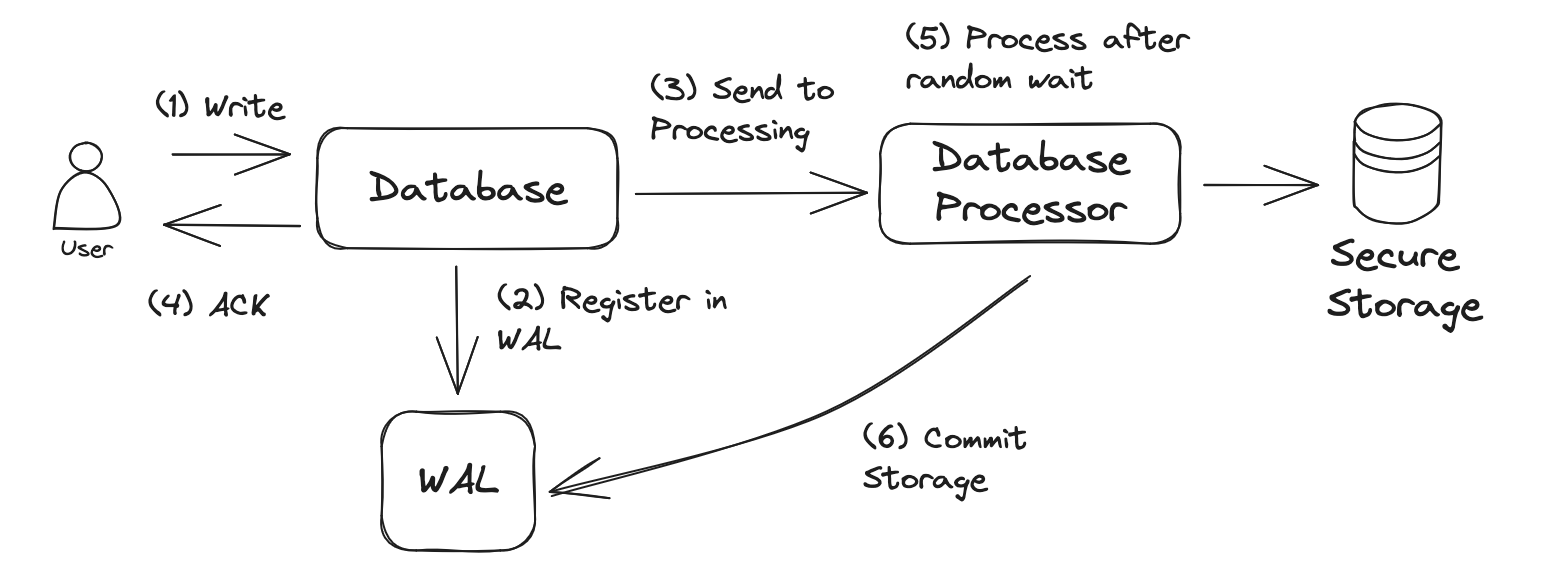
The most important part is being able to return an ack to the client without actually having to process the record.
Processing might fail and might be slow, but we don't care because the operation has been successfully stored into the WAL, this means that in case of failure we can just recover it.
In terms of the WAL system itself we introduce some important changes:
- We add a
commitoperations that's going to be used by the Database Processor once is has successfully stored the data into disk. - When the system
commitswe need to store the ID that has been committed into the system, as this is the idx that we need to use in case of failure. So this needs to be stored into the disk as well. In our implementation we are storing it in/tmp/wal/commit.log - We implement a new
getBacklogmethod that will be executed every time that the database boots up:- Get the latest index committed from
commit.log - Go through all the WAL files in the storage to see if there is any with an index bigger than the last committed one. This would mean that the data was stored in the WAL, but not processed by the processor. This operation needs to be replayed.
- Replay the operations that were not processed.
- Get the latest index committed from
How can we use the WAL technique outside a database ?
As we have seen, WAL's make a lot of sense in a database system. Also, taking into account that the technique is implemented as part of the engine, the operations are fast, can rely on the underlying operating system and they are not distributed.
Can we use this somewhere else though?
Yes. Let's imagine that we have the following use case:
- System with an API (like a REST microsystem)
- Critical and not trivial operations (might take some time to process)
- High load.
With these requirements it's very important to implement the responses and the error handling properly. As we've talked in other posts in this blog, the HTTP Status codes that will interest us are (from the server point of view) :
- HTTP 20X: Got your request and I accepted it. From now on it's my problem.
- HTTP 40X: Got your request, but it's wrong. Your problem. I'm not doing anything with it.
- HTTP 50X: Got your request, don't know what happened. Good luck figuring out.
As you can see from the descriptions I don't like the 50X family of status as they do not provide any kind of information about what's the next step. Did the service receive the operation? did it execute it? did it not? did it fail halfway ? Can the client retry? what's going to happen if it's a transactional operation ? is the service idempotent, so can I even retry?
So, understanding the differences between a database engine and a service with a REST/RPC API the proposal would be:
- System receives the request from the client.
- System validates the request.
- If the request is not valid, return a 400 Error (it's the client responsibility to fix and retry)
- If the request is valid, store the request safely.
- Return 201 or 202.
- Do the actual work.
We can easily identify that 2,3,4 describe the WAL technique. If we implement the WAL technique in our system we can safely ensure that the request will eventually get processed:
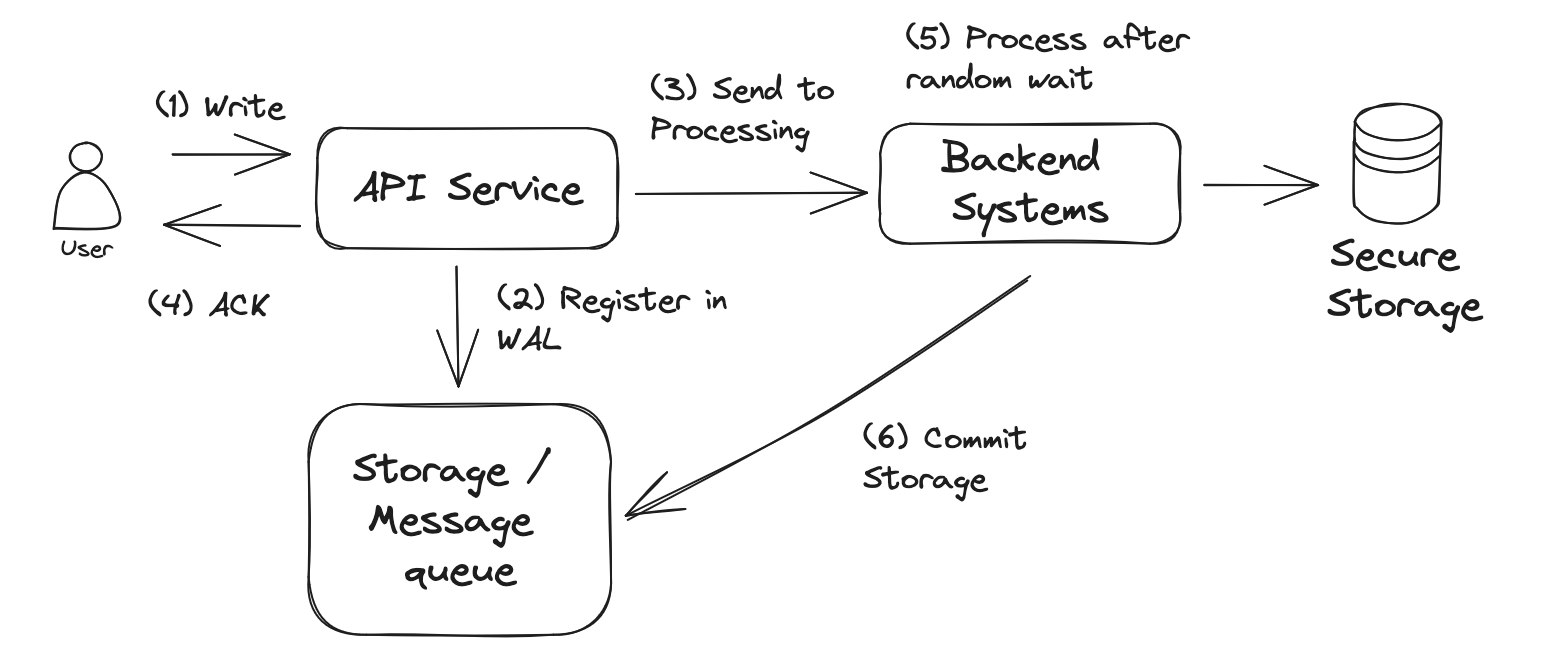
As you see this diagram is exactly the same as the one before, but just changing the component names from local components from the java system into more generic systems.
Result
This post describes the concepts around the Write Ahead Log technique, it explains how it might be used in a local system, like a datastore and then it extrapolates the concepts and technique into a bigger architecture.
Please remember that this blog post makes much more sense if you check the POC ode that you'll find in Github.
Also, the code in there is POC quality and for educative usage. While the technique is implemented and it works as expected, there are several issues (mostly focused on performance) that would need to be reimplemented to be used in a production or serious environment.
External resources
 facebook
facebook