Zero Trust Architectures
Why Zero Trust architectures exists, what it is and how it can be implemented.


This is the first time I'll be talking about security in this blog. While I'm no expert in security my experience shows that it is a critical part of a system, and unfortunately, one of the less understood or prioritized (Documentation being the other one, but that's another discussion).
Security in architectures is a huge topic. In this blog post I will write about my experiences with Zero Trust Architectures, given that I've participated in different implementation projects, so I have my opinions.
My initial experience with Zero Trust Architectures (ZTA from now on) came out of the blue, we were working with an IT system implement a fairly typical Perimeter Security model and suddenly we were tasked to implement a more robust and secure architecture.
ZTA is a complex topic and it requires you to understand a lot of concepts that might be similar, but different. When I was learning the basics I experienced some frustration as every step in the investigation led me to yet another rabbit hole. This is why I'm writing this post, hopefully it will make your ZTA adoption journey easier, or at least give you some important pointers.
So, this blog post is going to be long. It's structured like this:
- The problem.
- The Solution, Zero Trust Architectures.
- The big picture
- PDP & PEP Introduction.
- Authorization vs Authentication
- Getting closer to the details.
- Planes
- Identity and identity propagation.
- PDP Rules & implementation.
- Detailed picture of the architecture.
- Iterations to implement a ZTA Architecture.
- The big picture
- To sum up
- Bibliography and Links
Before getting into the big details and explanations I'm going to refer you to the NIST Special Publication 800-207 (pdf) which is, as far as I know, the document that puts all the concepts together to do some recommendations, basically it's the official guide.
If you do a fast search on the Internet you'll probably see tons of ads and vendor specific pages with their solutions. While some of them are much easier to read than the official NIST publication I will stick to the initial one, as it's vendor neutral and non biased.
The problem: Infrastructure too complex to protect.
The NIST publication states that enterprise's infrastructure has grown increasingly complex and this is definitely true. Any organization nowadays contains all kinds of integrated technologies, different distributed components; access from different roles in the company from different locations, with different devices; different deployment models, let it be if it's a local network, a public or private cloud, etc.
When we talk about IT security some people still think of a typical "perimeter security" based infrastructure; we have our servers inside our virtual network and we have big firewalls in all the ingress and egress points. But as I stated before, the infrastructure is getting more and more complex and it's getting tricky to identify the perimeter gates and to protect them. The big problem with "perimeter security" is that once an attacker gets into the perimeter it's a big game over for us; once inside, the attacker can get access to everything, as this model identifies any actor who is inside the perimeter as a valid and legit user.
A possible solution, don't trust anything, nor anybody.
ZTA is a set of principles, workflows and procedures that define systems that don't trust the actors by default, no matter if they are located inside or outside the network. So, trust is never granted implicitly but must be continually evaluated.
The big picture
Pragmatically ZTA is about preventing any kind of unauthorized access to resources inside the infrastructure. In order to achieve this there are two components that we need to talk about:
- Policy Decision Point (PDP): This component contains all the rules and knowledge in order to take a decision to allow a specific actor to access a specific resource. This is the component that provides Authorization into your system.
- Policy Enforcement Point (PEP): This is a component (or part of) that requests a decision to the PDP. In other words, a PEP small component in any application that contains any resource that must be protected. When it receives a request to access the resource it will request the access decision to the PDP.
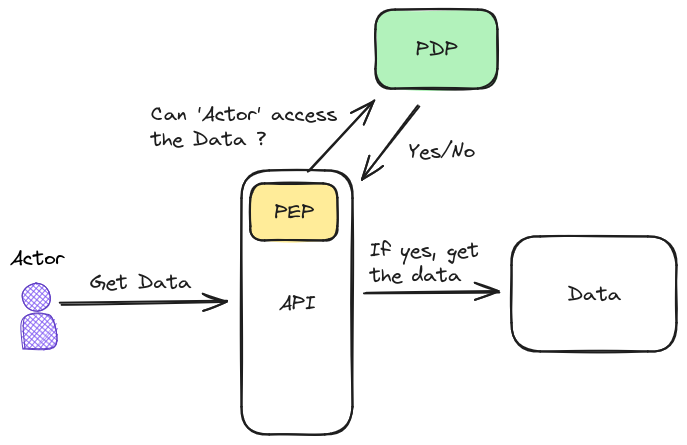
The diagram above is very simple and illustrative. While it's still missing some important parts of information we are going to use it to explain some of the basic concepts.
The Data is the resource that must be protected. Only some actors are authorized to read it, so the system designers wrapped it with an API system. The implementation of this API component has a PEP inside.
PEP is a concept, it's a point where the designers identified a possible access to a protected resource. In real life this subcomponent might be implemented by a library, a service mesh component or whatever solution the designers see fit. The important part is that it identifies requests and does not blindly accept them, but relies on the PDP to make the decision.
Getting closer to the details.
With this new knowledge we can draw a slightly more realistic diagram:
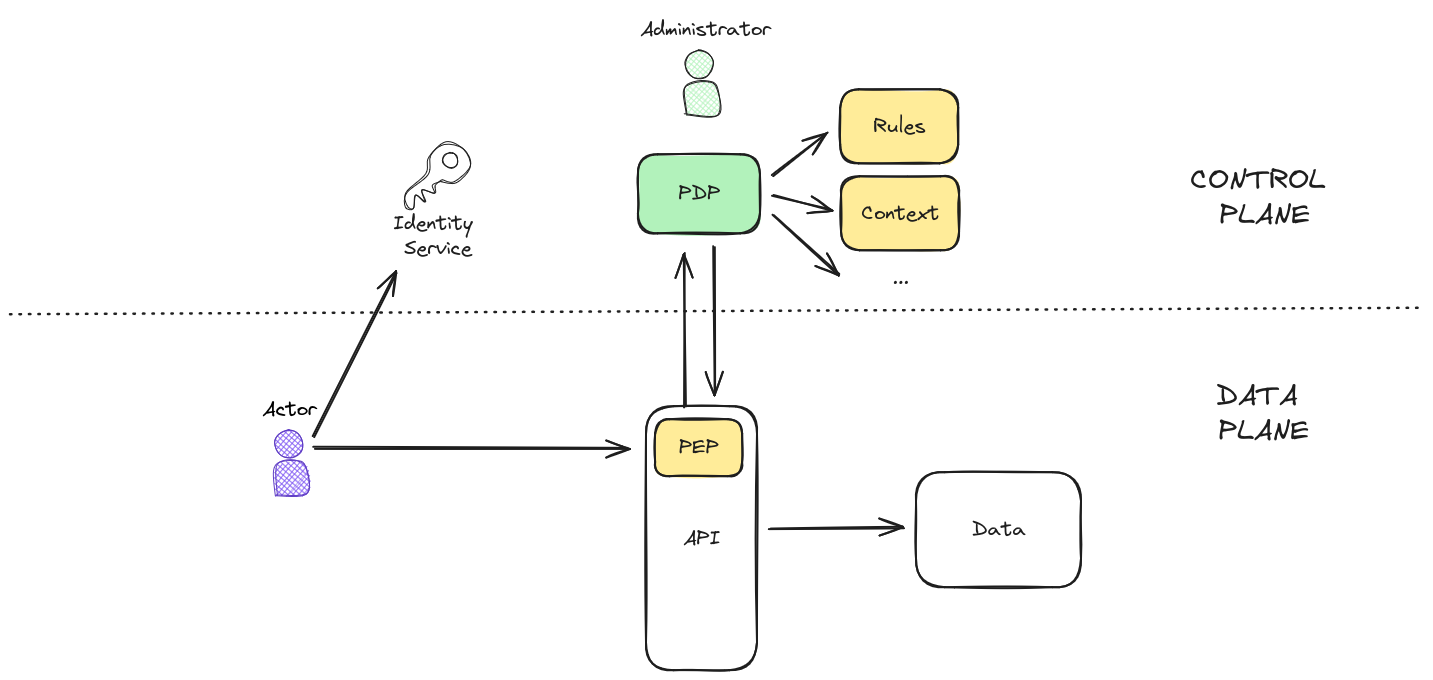
There are some new concepts in the previous diagram that I'm going to explain now.
Planes
In the previous diagram there is a dotted line that splits the drawing into two. These two subsystems need to work together, but they have very different use cases.
The Data Plane is where the Actors (you API's, databases, microservices, users ....) live and operate. It's where the business interactions happen, while the Control Plane is the "background" system that controls how the Data Plane works.
The PDP and the Identity Service are two components that will be used by the Data Plane, but it's important to note that the Data Plane components don't have any kind of control over the components of the Control Plane.
Identify and Identity Propagation
The Identity Service is a component that is able to provide an identity to a user (or system) that provides some tokens to identify themselves (username + password, security token, ...), so the Identity Service is the component that enables Authentication into your environment.
Nowadays identification is a tricky and complex issue. The identity service is usually a separate system that handles all the identification use cases while providing the maximum amount of security and flexibility possible. We are talking about safe storage of the identification tokens (secure password storage), cryptography use (to enforce secure communications, storing the secrets safely), all the typical use cases (create new user, remember forgotten password, ... ), etc.
While there is nothing stopping you to implement your own Identity Service it's considered a much better idea to use something that already exists. Do your own research as there are tons of solutions around, but as a rule of thumb you could use:
- If you're looking for an Open Source system that you can deploy yourself have a look at Keycloak.
- If you're in AWS, have a look at Cognito.
- If you're in Azure, have a look at Azure Active Directory External Identities.
- If you're in Google Cloud, have a look at Identity Platform.
Once an actor (a user via a webapp, or an internal microservice also called service to service) successfully validates its credentials to the Identity Service it will provide a Token that the actor will propagate with all the following interactions with the system. This token will be used by the PEP in order to ask the PDP for authorization.
Think of this token as your identity card that will give you access to some rooms, but not to others.
Of course this identification token is something that should:
- Be impossible to forge: The token should be signed by the Identity Service using cryptography. This means that an attacker would need to use the Identity Service keys in order to create a rogue identity.
- Have a due date: A Token should have a limited validity. If we create a token that lasts forever it could be captured by an attacker and then used without limits. When a token times out the system (using the libraries) should interact with the Identity Service to retrieve a new one automatically.
- Contain basic information: A token is something that should be able to carry some information with it. Probably the User/Service ID, and sometimes roles and some other characteristics. While this is useful we need to bear in mind that this Token will be propagated around a lot, so it's always a good idea to keep its size to a minimum.
At the time of writing this post the most popular format used for identification tokens is JWT (JSON Web Token), which is basically a JSON object with some defined information.
This JSON object has some interesting attributes, but for the sake of brevity I'm just going to focus on the requirements cited above.
- A JWT consists of three objects: A Header with some meta information. The Payload, with the actual data and the Signature with the cryptographic signature that proves that the data has not been tampered with and that it has been signed by a valid Identity Service.
- The Payload contains "claims", which are attributes that are optional. One of these is the exp, which sets an expiration date for the token. This means that after that date the token should be discarded and deemed invalid.
- As the latest point, the Payload has user defined information. So the Identity Service is able to put there as much data as it needs in order to provide information to the PDP when it needs to take the authorization decisions.
Bear that in mind.
https://redis.com/blog/json-web-tokens-jwt-are-dangerous-for-user-sessions/ and https://apibakery.com/blog/tech/no-jwt/ can give you some examples.
It's worth noting that, for example, Netflix has created their own Token for propagating the identify of the customers + microservices.
It's a long read, but definitely worth if you're interested in ZTA. That said, let's remember that Netflix requirements are huge and we really need to adapt the lessons to our "league" to avoid over-engineering, which is usually pretty bad in startups.
A note on leaking Identity Tokens
An important point that I'd like to make is that identity tokens (like JWT) are not encrypted by default. This means that if you get hold of one (via sniffing traffic) you can read the contents.
This is not a problem per se, but you might be leaking internal ids, addresses and meta information that an attacker could use in order to attack your system.
Also, note that if you use identity tokens in a use case where an external user can interact with your system, these tokens will go out of your Perimeter, so really anybody could get them and see what's inside.
This is why I recommend you to have the required minimum amount of information inside the token itself.
PDP Rules and types
Now that I've talked about the Identity tokens and its propagation, let me talk about the PDP. As shown in the diagrams, this component is the responsible to take decisions about who can access resources. It's basically a policy engine.
This policy engine will need to take idempotent decisions based on:
- The rules: These are going to be the authorization rules defined by your company and use cases. Who can write to this specific table of the database? who can read these money-sensible fields from the API? who can change billing information from clients?
- The actor: In order to deny or accept a request, the policy engine needs to know who's trying to perform that operations. This is where the Authentication Token that we described in the previous section comes in handy.
- Context: Depending on the rules and the use cases the PDP needs to be aware of the context in which the request takes form. Maybe something is not authorized after office hours? nobody is able to change the data in the API during Christmas?. Depending on your system the context might mean different things.
So, the rules are one of the biggest and more critical parts of this system, and as you can image this can get messy pretty fast. How do you define such rules in a sensible way?
There are, basically two conceptual ways of doing this:
- RBAC (Role Based Access Control): This authorization method leverages a lot on the actor. Each actor has one or more roles associated with their identity. Things like "admin", "sales", ... come into mind when thinking of roles. You basically grant some privileges to a specific role, and each use has one or more roles, so the user inherits these privileges.
- ABAC (Attribute Based Access Control): The Attribute based approach is more granular, but also more cumbersome to implement. Basically we are providing a user with the fain grained permissions to access the different resources. While this is a more complex approach it lets you handle more scenarios.
Now that we have the theory in place we can start to think how to actually implement this into a system.
Exactly like the Authorization scenario we could go for implementing our own PDP with our custom rules or use a 3rd party system.
In case we, sensibly, want to go for the 3rd party system I'd recommend you to have a look at the standard PDP open source implementation which is OPA, which provides a full set of integrations and it's own programming language rego to implement the rules. You'll find full details in the following link:

As you can imagine, this part is critical in the adoption of ZTA. Take your time and think carefully how you want to implement your PDP and which is the best approach for your use cases.
Detailed picture of the architecture
Once we have all these concepts clear lets get back to the ZTA. Let's put everything we've been talking together. It will result in something like this:
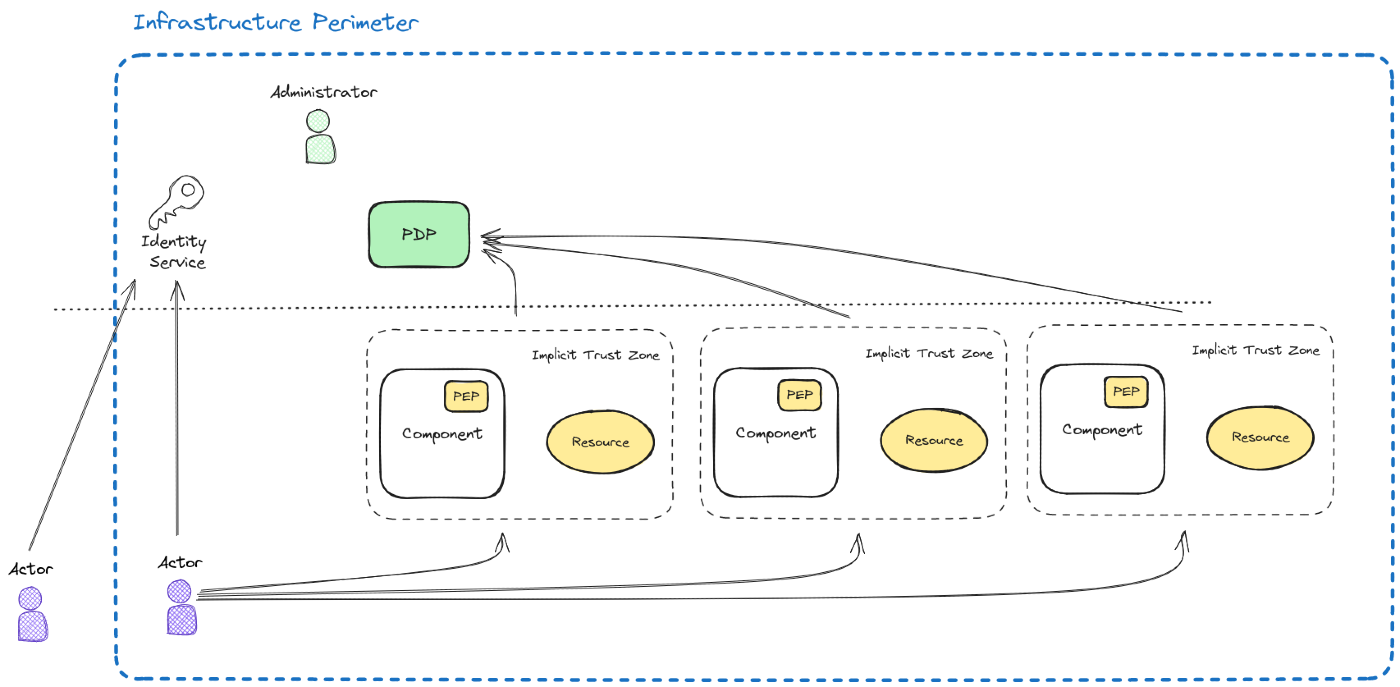
The only part that is new here are the Implicit Trust Zones. Basically we've moved from a global perimeter solution (a huge implicit trust zone) to lots of small perimeters, ideally one per resource that needs to be protected.
Without ZTA we'd have a single protection layer. In case of a successful attack the attacker would probably get access to the vast majority of our resources. After implementing ZTA the attacker would gain access to the perimeter, but in order to be able to access the data s/he would need to get a valid token per resource, which is something far more complex and complicated.
Implementation through iterations.
If you read through the full text you'll have a proper idea of what a ZTA is and the huge security advantages it provides.
There is also a big chance that you'll be slightly overwhelmed too about the number of extra components that you'll need to add into your architecture. None of them trivial. Don't worry though, as I'm going to propose you with an adoption plan now.
Using a ZTA has a huge impact on work that needs to be done by different teams from the company.
On one hand we need the infrastructure / devops team that will need to:
- Set up the Authorization system.
- PDP + Rules.
On the other hand the dev team will need to:
- Set up all the PEP's.
- Make the code react appropriately to the auth* possible failures.
ZTA is a set of ideas and flows. So, while there is no out-of-the-box solution to implement all of them at once we can easily create several steps to keep adapting and improving our architecture to these standards.
Possible ZTA adoption strategy.
This is not the only way to adapt an architecture to the ZTA flows. Probably you'll find different vendors with different approaches, but I'd recommend doing something like (specially if you go for the 100% open source approach):
- Identify the resources that need to be protected (API's, data, ...)
- Identify all the actors from inside / outside your network (Human actors via web frontend, company workers, admins, developers, microservices, batch jobs, ...)
- Set up an Authorization Service
- Set up the PDP service without rules.
- Identify / review what information you need to provide inside the Authentication Token:
- Start to implement PEP's in some services / frontends.
- Define some basic PDP rules
- Enforce the Authorization in the service PEP's.
- Go back to 5
From 1 to 2 we gather information and a proper understanding of what kind of resources our company has and what needs to be protected.
From 3 to 4 we have the very basic infrastructure setup. This only needs to be done once, and can be done in parallel with 1 & 2.
From 5 to 8 is an iterative approach to review what we have, add new protected resources and adapt the whole flow to them. We have the list of sensitive resources as a result of steps 1&2, let's pick just one and let's protect it.
In step 5 we identify what kind of information or meta-information we need to write in the Identification token. This is the information that will be provided to the PDP, so depending on the authorization rules we might need to add more context to the token, but remember that we don't want a very big token, so you'll have to draw a line here and see what kind of information needs to be propagated. So, for that specific resource, what does the PDP need to know about the actor that wants to use it?
In step 6 we define the rules. This is probably the tricky part where we need to play with the rules and make sure that the work we did in step 5 is good.
In step 7 we go to the system that handles owns the resource that needs to be protected, typically and API and we make sure that it's capable to identify all the incoming queries and is able to retrieve the authentication token from them and use the PDP in order to delegate the authorization request.
In step 8 we start to really enforce the PEP to use the PDP and react to authorization failures and make sure that the flow is correct.
Once we have that specific resource protected (and hence, creating its Implicit Trust Zone we can move forward to the next resource, so we'll identify the next resource that we want to protect and go back to step 5 to restart the process.
This approach lets you tackle resources one by one, while learning from the process without putting too much process in the dev/devops team at once.
To sum up
As you've seen, ZTA are a complex topic which encompasses several components, flows and concepts.
Hopefully this post will serve you as an initial guideline that will get you started in the main points and give you pointers.
Related bibliography and some other interesting links:
There are tons of products, talks, articles and videos about ZTA. These are some of my favorites and that ones that were more helpful when I initially dived into the topic (but remember that the guideline should always be the NIST document linked in the beginning of this post):


